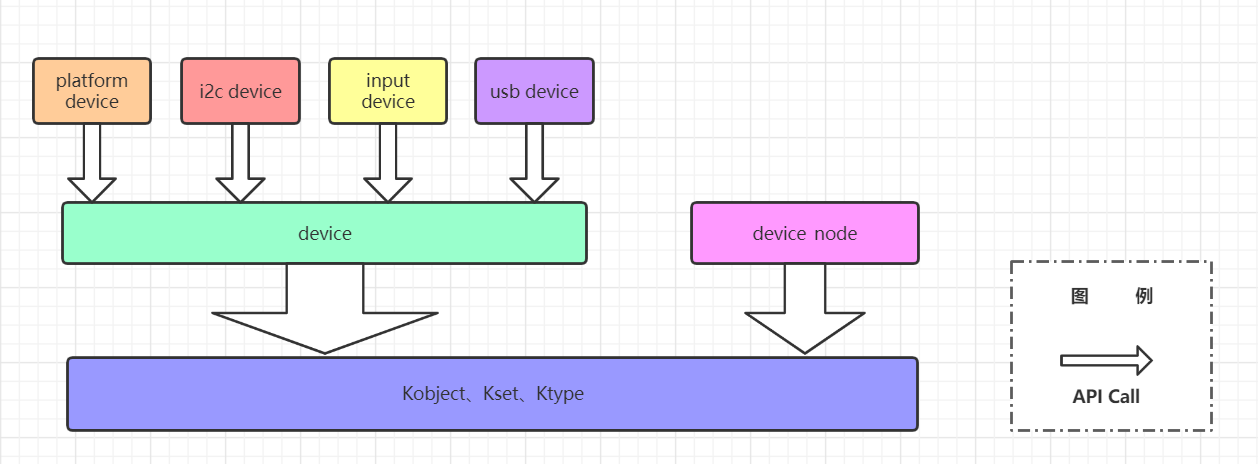
对于Linux的各种机制,学习它的最佳方法,我认为是先掌握其用法,再去探究其背后的实现。那么,在真正介绍Linux设备驱动程序之前,我们先探讨设备驱动提供了什么,它是怎么被使用的。本节我们会以键盘这一物理设备为例,来探究应用程序是通过键盘驱动程序提供的设备节点去获取按键键值和动作这一过程。
在计算机系统中分为两类程序,一类是应用程序,负责提供策略,直接为用户服务。比如:Word是一款文本编辑器,当我们新建一个文档,敲击键盘时,Word就会从操作系统中获取到我们敲击键盘对应的字符,并显示在页面中。另一类程序是操作系统,它包括了设备驱动、内存管理、进程调度、文件系统等。Word获取的字符是从操作系统中获取的,那么当敲击键盘时,操作系统又是如何获取到键盘上对应的字符的呢?
一、什么是设备节点
人和人之间沟通桥梁是语言。同样,应用程序和设备驱动程序沟通也需要一个桥梁。这个桥梁就是设备节点。在Linux设计哲学这篇文章中,我们提到Linux系统的“一切皆文件”的设计思想。意思指对于Linux系统,所有的IO资源都是文件,包括文件、目录、硬盘、设备等。那么,键盘作为计算机系统中的一款输入设备,操作系统同样也把它抽象了文件,要想获取用户从键盘上输入的数据时,只需要读取键盘提供的设备节点即可。
在Linux系统中,键盘作为输入设备,其对应的设备节点位于"/dev/input"下。在这个文件夹下有很多以event打头的文件,这些就是所有input设备的设备节点。如何确定哪个是键盘的设备节点呢?将键盘连接到树莓派上,打开终端,执行“sudo cat /dev/input/event0”,敲击键盘,如果没有输出,就换下一个节点,直到找到有输出的节点,那这个节点就是键盘对应的设备节点。
二、如何从设备节点中获取数据
上文中,我们确定了键盘对应的设备节点,在这一小节中,我们将写一个小的程序来从该设备节点中获取按下按键之后设备驱动上报的数据,并最终解析出对应的键值。
前面也提到过,操作系统之所以把IO都抽象成了文件,最大的好处就是可以通过统一的接口来访问这个文件,从而和不同的设备沟通。这些统一的接口就是操作系统针对文件操作对外提供的一组系统调用:open函数、read函数、write函数等。比如,如果需要从一个设备中获取数据,只需要调用read函数去读取该设备对应的设备节点就可以了,当然在read之前,要先调用open函数打开。现在以获取键盘输入为例来介绍。
2.1 打开设备节点
在读取设备节点的数据之前,要先调用open函数打开设备节点。open函数的具体用法可以参考链接。简单描述如下:
函数声明:
int open(const char *pathname, int flags);
需要包含的头文件:
#include
参数:
- 第一个参数(const char *pathname):表示需要打开的文件路径
- 第二个参数(int flags):表示打开文件的方式,比如,"O_RDONLY" ——只读打开;"O_WRONLY"——只写打开;"O_RDWR"——读、写打开,等。
返回值:
如果打开成功,则返回该文件的文件描述符,以供read,write等函数使用。否则,返回-1。
那么,要打开键盘的设备文件(假设是"/dev/input/even10"),则需要以下代码:
int keys_fd;
keys_fd = open("/dev/input/even10", O_RDONLY);
if(keys_fd <= 0)
{
printf("open /dev/input/event10 device error!\n");
return -1;
}2.2 读取设备节点的数据
读取设备节点需要使用read函数,具体使用方法可以参考链接。简单介绍如下:
函数声明:
ssize_t read(int fd, void *buf, size_t count);
需要包含的头文件:
#include
参数:
- 第一个参数(int fd):要打开文件的文件描述符,来源一般是上述open函数的返回值。
- 第二个参数(void *buf):读取到的数据存放的起始位置指针
- 第三个参数(size_t count):要读取的数据字节数
返回值:
- 如果读取成功,则返回实际读取到的字节数
- 如果读取失败,则返回-1
- 如果返回值小于第三个参数count,则表示已经读取到文件结尾,返回值表示实际读取的字节数。
在读取键盘的例子中,我们循环读取键盘设备的文件节点,并将设备保存到一个char buf[24]的数组中去。具体代码如下:
char buf[24];
while(1)
{
if(read(keys_fd, buf, 24) == 24)
{
// 成功的从设备节点中获取到了24个字节
...
}
}根据read函数用法,当要读取24个字节,且read函数的返回值是24时,表示成功的从设备节点中获取到了24个字节。
2.3 分析从设备节点获取的数据
为什么这里要从键盘的设备驱动获取24个字节呢?这是因为正常情况下,从键盘设备节点获取的数据实际上是一个struct input_event结构。其定义为:
struct input_event {
struct timeval time;
__u16 type;
__u16 code;
__s32 value;
};显然,上述结构体的大小为24。
这里需要理解的是:设备节点是设备驱动程序提供的,且设备节点的数据是设备驱动写入的,而且写入时,是以上述结构的规则写入的,这是双方通过<linux/input.h>约定好的,那么应用程序去设备节点中读取数据之后,也需要按照上述结构去解析数据。那这个结构具体是什么意思呢?
struct timeval time:其大小为16个字节,具体意义暂时不考虑。__u16 type:其大小为2个字节,表示input设备的类型,比如:EV_KEY表示上报的是键盘类型的数据,EV_REL表示相对路径,鼠标就属于这种类型,还是其他等等。__u16 code:其大小为2个字节,表示事件的代码。比如,如果type为EV_KEY,那么该代码code为设备键盘代码。code值实际上是应用程序和驱动程序约定好的一些固定的值,它可取的值位于include/uapi/linux/input-event-codes.h中。举例来讲,根据Linux源码下的include/uapi/linux/input-event-codes.h文件的第91行#define KEY_Q 16,如果键盘上按下或松开了Q键,那么键盘的驱动程序上报的code值应该是16;反之,如果应用程序获取到的值是19,那么,表示用户按下或松开了键盘上的Q键。__s32 value:其大小为4个字节,事件的值。如果事件的类型代码是EV_KEY,当按键按下时值为1,松开时值为0;
根据上述解释,我们可以添加以下代码来解析从设备节点中获取的数据。
if(t.type == EV_KEY) // 我们只关心input event类型为EV_KEY(按键)的消息
if(t.value == 0 || t.value == 1)
{
printf("key %d %s\n",
t.code, // t.code表示按下或松开了哪个按键
(t.value) ? "Pressed" : "Released"); // t.value表示按下还是松开了相应的按键
}2.4 关闭设备节点
在从设备节点获取数据完成后,务必调用close函数,来关闭设备节点。即
close(keys_fd);三、实验演示
将上述程序放到树莓派中,命名为keyboard.c。然后,执行以下命令编译:
gcc -o keyboard keyboard.c执行sudo ./keyboard,运行程序,然后按下、松开连接于树莓派的键盘上的Q键,会得到如下输出:
pi@raspberrypi:~/Source/keyboard $ sudo ./keyboard
key 16 Pressed
key 16 Released
key 16 Pressed
key 16 Released这里输出按下或者松开了code为16的按键。打开kernel代码中include/uapi/linux/input-event-codes.h,搜索"KEY_Q",在第91行,我们找到了以下代码:
#define KEY_Q 16可以确认,16就是按键Q的值。
四、总结
- 设备驱动程序提供了设备节点;
- 设备节点作为应用程序和驱动程序(操作系统)沟通的桥梁,用来使双方传输数据;
- 在用户空间(应用程序中)可以通过操作系统提供的文件系统相关的系统调用(open,read,write等函数)去访问设备节点。
- 对于input设备来讲,应用程序和驱动程序约定好,以
struct input_event来传递数据。